Propensity scores are used to explore causal relationships using observational data. While some claim they are almost as good as a randomized trial, in this Deep Dive, F. Perry Wilson, MD, explains how they work -- and when they don't.
Today we're going to dissect a statistical topic rather than a medical study. As requested by this highly unscientific twitter poll – let's talk propensity scores.
What form of statistical magic can take an observational study and turn it into a randomized trial? The magic of wishful thinking.
I've become a bit skeptical about propensity scores of late, but, full disclosure, I engaged in some propensity score matching in my youth:

The problem that propensity scores try to solve is ubiquitous in medical research. You want to know if an exposure causes a certain outcome, but all you have is observational data. As an example, let's say you want to know if marijuana use leads to depression.
The raw data shows a clear association. People who smoke pot are more likely to become depressed.

But your skeptical brains must be wondering: "wait a second – maybe people with certain traits that lead to depression might decide to use marijuana." The raw evidence might be good enough for your local Senator, but not for us.
Now, we can identify all sorts of factors that are associated with pot smoking – things that affect your propensity to smoke pot. Being male, being white, and smoking tobacco were all strongly associated with pot use in this study, which, by some coincidence, addresses the very issue we're discussing.

Now, we could adjust for all of those factors. That's a standard practice - but there is a cost. Each variable you adjust for makes your effect estimate less precise – the confidence intervals around your estimate widen.
I simulated some data looking at the relationship between pot use and depression, assuming a pretty large raw effect size.
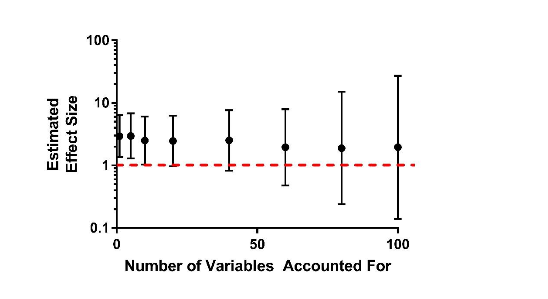
I also simulated 100 variables that are linked with pot use, but not depression. As you can see, as I adjust for more and more of those variables, my estimate of marijuana's link to depression gets less and less precise. And this problem gets bigger the smaller the study is.
Eventually, the confidence intervals are so wide that you have no idea what's going on, and you've shot yourself in the foot with your fancy statistics.
OK, so instead of multivariable adjustment, you build a propensity score. A propensity score is a single number that integrates all the factors associated with exposure. It allows us to take those 100 variables, and condense them into a single variable that gives the probability that you are a pot-smoker. We can use that single variable to avoid paying the statistical price of adjusting for 100 things. Now we can just adjust for one.
Or, we can find people with similar propensity scores, and match them together.
Take Paul and Judy here.

Our model might say that both of them have a 30% chance of being a pot smoker based on our huge 100-variable model.
Now, in actuality, our model isn't perfect. Paul does smoke Pot, and Judy does not.
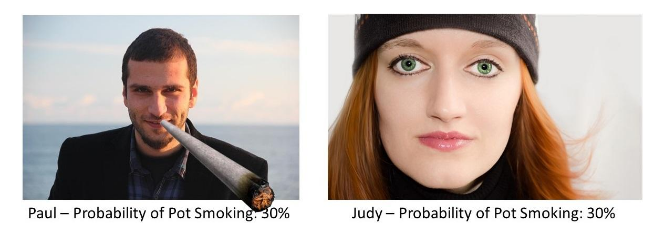
But, on average, they share an overall risk for pot smoking – that's why they have the same propensity score. It's like they were both in a randomized trial and one got assigned to smoke pot while the other got assigned to boring old usual care. We can compare their outcomes to get a more fair estimate of the true effect of pot on depression.
Well, that's the idea at least. Propensity-score proponents would argue this is almost like a randomized trial – all the covariates end up being the same except the treatment.
Of course, really all the measured covariates end up the same. And trust me, it's the unmeasured covariates that come back to bite you.
The other thing to point out is that propensity-score matching is only as good as your ability to predict whether the individual will be exposed or not. If your predictive model is useless, matching is useless.
And paradoxically, if your prediction model is too good, propensity matching doesn't work either. Imagine you can perfectly predict who will be a pot smoker and who won't. Well, then there isn't anyone to match. All the people you predict smoke pot do smoke pot so there is no comparison group.
And I think that's the thing that bothers me most. This is a statistical technique that depends on good but not great model-building. And that just rubs me the wrong way intuitively. You're essentially pretending that, since you've accounted for everything that leads to pot, all that is left is random. But is any choice in life truly random? Yup – propensity scores lead to existential crises.
In the end, I've come around to two conclusions. First, I'm not convinced propensity score techniques offer you much more than multivariable adjustment, except in certain situations where it seems a little like cheating.
And second, randomized trials are like New Haven pizza. We can try all we want to approximate them, but nothing is really as good.
, is an assistant professor of medicine at the Yale School of Medicine. He is a �������� reviewer, and in addition to his video analyses, he authors a blog, . You can follow .